Backtrack is about to be a new performance tool, focused on revealing and solving scheduling and delay problems. Those are big offenders of performance, very hard to track, and hidden from conventional profilers.
To find out how long and what all has to happen to reach a certain point – an objective, just add a simple instrumentation marker. When hit during run, it’s added to a list you can then pick from and start tracing to its origin. Backtrack follows from the selected objective back to the originating user input event that has started the whole processing chain.
The walk-back crosses runnables and their wait time in thread event queues, but also network requests and responses, any code specific queues such as DOM mutations, scheduled reflows or background JS parsing 1), monitor and condvar notifications, mutex acquirements 2), and disk I/O operations.
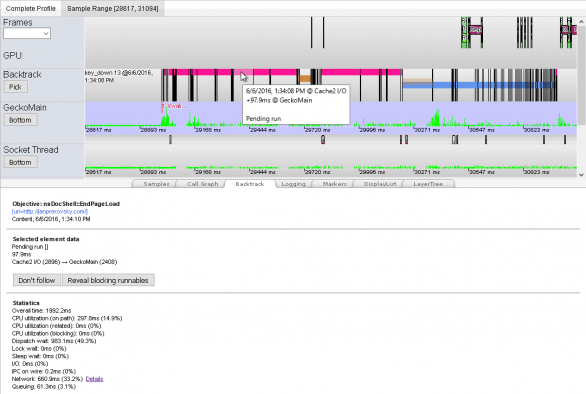
Visually the result is a single timeline – we can call it a critical path – revealing wait, network and CPU times as distinct intervals involved in reaching solely the selected objective. Spotting mainly dispatch wait delays is then very easy. The most important and new is that Backtrack tells you what other operations or events block (makes the critical path wait) and where from have been scheduled. And more importantly, it recognizes which of them are (or are not) related to reaching the selected objective. Those not related are then clear candidates for rescheduling.
To distinguish related and unrelated operations Backtrack captures all sub-tasks that are involved in reaching the selected objective. Good example is the page first paint time – actually unsuppress of painting. First paint is blocked by loading more than one resource, the HTML and head referenced CSS and JS. These loads and their processing – the sub-tasks – happen in parallel and only completion of all of them unsuppresses the painting (said in a very simplified way, of course.) Each such sub-task’s completion is marked with an added instrumentation. That creates a list of sub-objectives that are then added to the whole picture.
Future improvements:
- Backtrack could be used in our perfomance automation. Except calculation of time between an objective and its input source event, it can also calculate CPU vs dispatch delays vs network response time. It could also be able to filter out code paths clean of any outer jitter.
- Indeed, networking has strong influence to load times. Adding more detailed breakdown and analyzes how well we schedule and allocate network resources is one of the next steps.
- Adding PCAPs or even let Backtrack capture network activity like Wireshark directly from inside Firefox and join it with the Gecko Profiler UI might help too.
The current state of Backtrack development is a work in active progress and is not yet available to users of Gecko Profiler. There are patches for Gecko, but also for the Cleopatra UI and the Gecko Profiler Add-on. The UI changes, where also the analyzes happens, are mostly prototype-like and need a clean up. There are also problems with larger memory consumption and bigger chances to hit OOMs when processing the captured data with Backtrack captured markers.
1) code specific queues need to be manually instrumented
2) with ability to follow to the thread that was keeping the mutex for the time you were waiting to acquire it
The post Backtrack meets Gecko Profiler appeared first on mayhemer's blog.










